
前言#
Go の紹介#
- Google オープンソース
- コンパイル型言語
- 21 世紀の C 言語
2005 年にマルチコアプロセッサが登場し、他の言語はすべてシングルコア時代に誕生しました。Go は生まれつきマルチコアの並行性を考慮しています。
特徴:
- 文法が簡潔(25 のキーワードのみ、Python よりも簡潔で、フォーマットが自動で、相互に読みやすい)
- 開発効率が高い
- 実行性能が良い(Java に近い)
発展:
百度自動運転、小プログラム
テンセントのブルーウェーブ、マイクロサービスフレームワーク
知乎は最初 Python で書かれましたが、後に負荷に耐えられず、Go で再構築して 80% のリソースを節約しました。
コースの紹介#
8 週間の基礎
3 つの実戦プロジェクト
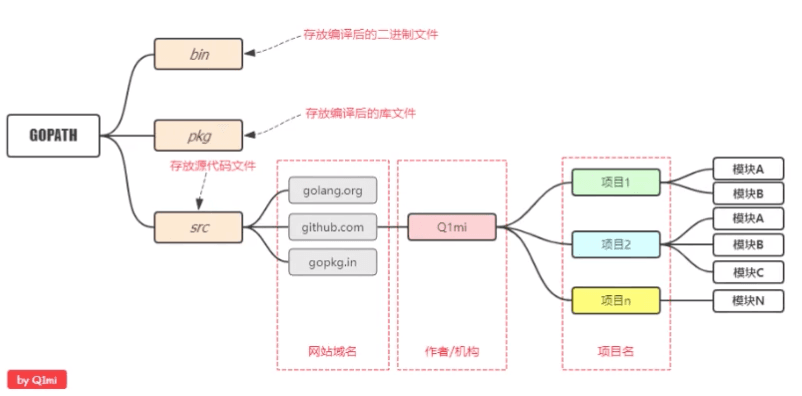
Go プロジェクト構造#
個人開発者
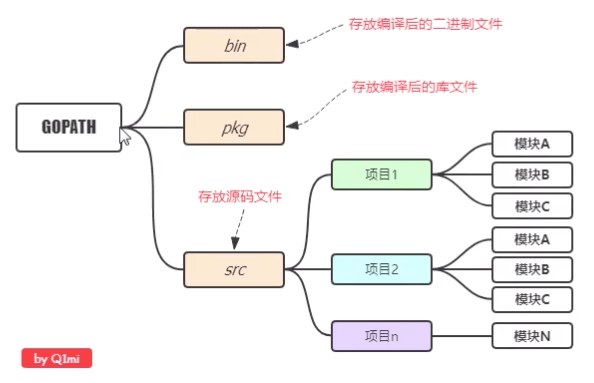
流行の方法
Helloworld#
go build
Windows では exe が生成され、macOS では実行可能ファイルが生成されます。
go install
install は build の後に bin に移動することに相当します。
go run
スクリプトを実行します。
クロスプラットフォームの交差コンパイルをサポートします。
// wincmd SET, macos export
export CGO_ENABLED=0 //CGOを無効にする
export GOOS=linux //ターゲットプラットフォームをlinux, windows, darwinに設定
export GOARCH=amd64//ターゲットプロセッサアーキテクチャはamd64
go build
export CGO_ENABLED=0 GOOS=linux GOARCH=amd64
go build
変数と定数#
関数外では文を記述できません。
識別子:アルファベット、数字、アンダースコアで構成され、数字で始まってはいけません。
キーワードや予約語は変数名として使用しないことをお勧めします。
変数#
初期化#
数字はデフォルトで0、文字列はデフォルトで空、ブールはデフォルトでfalse、スライス、関数、ポインタはデフォルトでnilです。
var 変数名 型 = 式
var name string = "Q1mi"
var age int = 18
var name, age = "Q1mi", 20 //値に基づいて型を推論します
var (
a string
b int
c bool
d float32
)
関数外に書かれたものはグローバル変数です。
関数内でローカル変数を宣言する簡略形は
n := 10
m := 200
fmt.Println(m, n)
注意:Golang では非グローバル変数の宣言は必須です。そうでないとコンパイルが通りません!
fmt.Print()
fmt.Printf()
fmt.Println() //改行
保存時に自動でフォーマットされます。
命名規則#
var studentName string
Golang は小文字のキャメルケース命名を使用します。
匿名変数#
短いアンダースコアで受け取り、名前空間を占有せず、メモリを割り当てません。
x, _ = foo()
_, y = foo()
定数#
const pi = 3.14
iota#
定数カウンターで、新しい行の定数宣言が追加されるたびにカウントされます。注意:1 行です。
const (
n1 = iota //0
n2 //1
n3 //2
n4 //3
)
const (
n1 = iota //0
n2 //1
_ //2 しかし破棄されます
n3 //3
)
定義の数量級#
const (
_ = iota
KB = 1 << (10 * iota)
MB = 1 << (10 * iota)
GB = 1 << (10 * iota)
TB = 1 << (10 * iota)
PB = 1 << (10 * iota)
)
<< 左シフト演算子、2 進数の 1 を 10 ビット左にシフトすると 1024 になります。
基本データ型#
整数型は以下の 2 つの大きなカテゴリに分かれます:長さによる分類:int8、int16、int32、int64
対応する符号なし整数型:uint8、uint16、uint32、uint64
uint8 は byte、int16 は short、int64 は long です。
特殊整数型#
uint intはシステムに応じて 32 または 64 を判別します。
uintptrはポインタで、メモリアドレスを格納します。
進数#
Golang では直接 2 進数を定義できませんが、8 進数と 16 進数は可能です。
// 十進数
var a int = 10
fmt.Printf("%d \n", a) // 10
fmt.Printf("%b \n", a) // 1010 プレースホルダー%bは2進数を示します。
// 八進数 0で始まります
var b int = 077
fmt.Printf("%o \n", b) // 77
// 十六進数 0xで始まります
var c int = 0xff
fmt.Printf("%x \n", c) // ff
fmt.Printf("%X \n", c) // FF
fmt.Printf("%T \n", c) // 出力タイプ
fmt.Printf("%v \n", c) // 変数値を出力、任意のタイプ
浮動小数点数#
golang では小数はデフォルトでfloat64です。
math.MaxFloat64 // float64の最大値
ブール#
デフォルトは false で、変換は許可されていません。
文字列#
二重引用符のみ使用可能で、単一引用符は文字を示します。
| エスケープ | 意味 |
|---|---|
| \r | 行の先頭に戻る |
| \n | 改行(下行同列) |
| \t | タブ |
// Windowsでのパスのエスケープ
s := "D:\\Documents\\A"
// バッククオートはそのまま出力し、複数行の文字列を示します。
s := `
asda
asd
`
s := "D:\Documents\A"
len(str)
ss := s1 + s2
ret := strings.Split(s3, "\\")
ret = strings.Contains(s3, "abcd")
ret = strings.HasPrefix(s3, "abcd")
ret = strings.HasSufix(s3, "abcd")
ret = strings.Index(s3, "c")
ret = strings.LastIndex(s3, "c")
ret = strings.Join(a, b)
英字はbyte、他の言語系(例えば中国語の文字)はruneで、実際にはint32で 3 バイトを占めます。
文字列の反復
for _, char := range str {
fmt.Printf("%c", char)
}
文字列は直接変更できず、他のタイプに変換して処理する必要があります。
s3 := []rune(s2) //スライス
s3[0] = 'e' //変更
s4 := string(s3)
フロー制御#
if#
if 表現1 {
分岐1
} else if 表現2 {
分岐2
} else{
分岐3
}
// ローカル変数scoreはif内でのみ有効で、メモリ使用量を減らします。
if score := 65; score >= 90 {
fmt.Println("A")
} else if score > 75 {
fmt.Println("B")
} else {
fmt.Println("C")
}
for#
golang には for のみがあります。
for 初期文;条件式;終了文{
ループ本体文
}
for i := 0; i < 10; i++ {
fmt.Println(i)
}
初期文と終了文は省略可能で、while に相当します。
i := 0
for i < 10 {
fmt.Println(i)
i++
}
無限ループ
for {
ループ本体文
}
break、goto、return、panic文を使用してループを強制終了します。
反復#
for rangeは配列、スライス、文字列、マップ、チャネルを反復します。
for i,v := range s{
fmt.Println(i, v)
}
- 配列、スライス、文字列はインデックスと値を返します。
- マップはキーと値を返します。
- チャネルはチャネル内の値のみを返します。
switch#
finger := 3
switch finger {
case 1:
fmt.Println("親指")
fallthrough
case 2:
fmt.Println("人差し指")
case 3:
fmt.Println("中指")
case 4:
fmt.Println("薬指")
case 5:
fmt.Println("小指")
default:
fmt.Println("無効な入力!")
}
fallthrough文法は、条件を満たす case の次の case を実行することができ、C 言語の case 設計との互換性を持たせるためのものです。
switch n := 7; n {
case 1, 3, 5, 7, 9:
fmt.Println("奇数")
case 2, 4, 6, 8:
fmt.Println("偶数")
default:
fmt.Println(n)
}
goto#
goto文はラベルを介してコード間の無条件ジャンプを行います。goto文はループを迅速に抜けたり、重複した退出を避けたりするのに役立ちます。Go 言語ではgoto文を使用することで、いくつかのコードの実装プロセスを簡素化できます。例えば、二重ネストの for ループを抜ける場合:
var breakFlag bool
for i := 0; i < 10; i++ {
for j := 0; j < 10; j++ {
if j == 2 {
// 退出ラベルを設定
breakFlag = true
break
}
fmt.Printf("%v-%v\n", i, j)
}
// 外側のforループの判断
if breakFlag {
break
}
}
簡素化すると:
for i := 0; i < 10; i++ {
for j := 0; j < 10; j++ {
if j == 2 {
// 退出ラベルを設定
goto breakTag
}
fmt.Printf("%v-%v\n", i, j)
}
}
return
// ラベル
breakTag:
fmt.Println("forループを終了")
演算子#
++(インクリメント)と--(デクリメント)は Go 言語では独立した文であり、演算子ではありません。
// 論理演算
&&
||
!
// ビット演算
&
|
^
<<
>>
// 代入
+=
-=
<<=
配列#
初期化#
配列は宣言時に決定され、使用時に配列メンバーを変更できますが、配列のサイズは変更できません。
var a [3]int
var a [3]int
var b [4]int
a = b //このようにはできません。なぜならaとbは異なる型だからです。
配列はインデックスを介してアクセスでき、インデックスは0から始まります。最後の要素のインデックスはlen-1です。範囲外アクセス(インデックスが合法範囲外)は、範囲外アクセスを引き起こし、panic します。
var testArray [3]int //配列はint型のゼロ値で初期化されます。
var numArray = [3]int{1, 2} //指定した初期値を使用して初期化します。
var cityArray = [3]string{"北京", "上海", "深圳"} //指定した初期値を使用して初期化します。
var numArray = [...]int{1, 2} //値に基づいて配列の長さを推論します。
var cityArray = [...]string{"北京", "上海", "深圳"}
a := [...]int{1: 1, 3: 5} //インデックスを指定して初期化します。
fmt.Println(a) // [0 1 0 5]
for index, value := range a {
fmt.Println(index, value)
}
多次元配列#
a := [3][2]string{
{"北京", "上海"},
{"広州", "深圳"},
{"成都", "重慶"},
}
多次元配列は最初のレイヤーのみ
...を使用してコンパイラに配列の長さを推論させることができます。
配列は値型であり、代入や引数渡しは配列全体をコピーします。したがって、コピーの値を変更しても元の値は変更されません。
- 配列は「==」、「!=」演算子をサポートします。なぜなら、メモリは常に初期化されているからです。
[n]*Tはポインタ配列を示し、*[n]Tは配列ポインタを示します。
スライス#
配列の制限、長さが固定です。
スライス(Slice)は、同じ型の要素を持つ可変長のシーケンスです。これは配列型に基づいているラッパーです。非常に柔軟で、自動拡張をサポートします。
スライスは参照型であり、その内部構造にはアドレス、長さ、容量が含まれます。スライスは通常、データ集合を迅速に操作するために使用されます。
初期化#
var a = []string //文字列スライスを宣言
var b = []int{} //整数型スライスを宣言し初期化
var c = []bool{false, true} //ブール型スライスを宣言し初期化
var d = []bool{false, true} //ブール型スライスを宣言し初期化
スライスが指すとき、値は空ではありません。
a1 := [...]int{1, 3, 5, 7, 9, 11, 13}
s3 := a1[0:4] //左包み右非包み、インデックスは0-3のスライス
len(s3) // 4 スライスの長さ
cap(s3) // 7 容量=元の配列スライスのポイントから末尾までの長さ
a[2:] // a[2:len(a)]と同等
a[:3] // a[0:3]と同等
a[:] // a[0:len(a)]と同等
元の配列の要素が変更されるとスライスも変わります。参照型です。
a[low : high : max]
a := [5]int{1, 2, 3, 4, 5}
t := a[1:3:5] //t:[2 3] len(t):2 cap(t):4
構造体と簡単なスライス表現a[low: high]は同じ型、同じ長さ、同じ要素のスライスです。また、得られた結果のスライスの容量はmax-lowに設定されます。完全なスライス表現では最初のインデックス値(low)のみ省略可能で、デフォルトは 0 です。
make()#
スライスを動的に作成します。
make([]T, size, cap)
a := make([]int, 2, 10) // 初期値は0
空スライスの判断#
スライスが空かどうかを確認するには、len(s) == 0を使用して判断し、s == nilを使用して判断すべきではありません。
スライス間は比較できず、==演算子を使用して 2 つのスライスがすべて等しい要素を含むかどうかを判断することはできません。スライスの唯一の合法的な比較操作はnilとの比較です。nil値のスライスには基盤となる配列がなく、nil値のスライスの長さと容量は両方とも 0 です。しかし、長さと容量が両方とも 0 のスライスが必ずnilであるとは言えません。
代入#
s1 := make([]int, 3) //[0 0 0]
s2 := s1 //s1をs2に直接代入し、s1とs2は同じ基盤配列を共有します。
s2[0] = 100
fmt.Println(s1) //[100 0 0]
fmt.Println(s2) //[100 0 0]
append()#
var s []int
s = append(s, 1) // [1]
s = append(s, 2, 3, 4) // [1 2 3 4]
s2 := []int{5, 6, 7}
s = append(s, s2...) // [1 2 3 4 5 6 7]
var で宣言されたゼロ値スライスは、
append()関数で直接使用でき、初期化は不要です。
var s []int
s = append(s, 1, 2, 3)
各スライスは基盤となる配列を指し、この配列の容量が十分であれば新しい要素を追加します。基盤となる配列が新しい要素を収容できない場合、スライスは自動的に一定の戦略に従って「拡張」されます。このとき、そのスライスが指す基盤となる配列は変更されます。「拡張」操作は通常append()関数の呼び出し時に発生するため、通常は元の変数でappend関数の戻り値を受け取る必要があります。
func main() {
//append()で要素を追加し、スライスを拡張します。
var numSlice []int
for i := 0; i < 10; i++ {
numSlice = append(numSlice, i)
fmt.Printf("%v len:%d cap:%d ptr:%p\n", numSlice, len(numSlice), cap(numSlice), numSlice)
}
}
出力
[0] len:1 cap:1 ptr:0xc0000a8000
[0 1] len:2 cap:2 ptr:0xc0000a8040
[0 1 2] len:3 cap:4 ptr:0xc0000b2020
[0 1 2 3] len:4 cap:4 ptr:0xc0000b2020
[0 1 2 3 4] len:5 cap:8 ptr:0xc0000b6000
[0 1 2 3 4 5] len:6 cap:8 ptr:0xc0000b6000
[0 1 2 3 4 5 6] len:7 cap:8 ptr:0xc0000b6000
[0 1 2 3 4 5 6 7] len:8 cap:8 ptr:0xc0000b6000
[0 1 2 3 4 5 6 7 8] len:9 cap:16 ptr:0xc0000b8000
[0 1 2 3 4 5 6 7 8 9] len:10 cap:16 ptr:0xc0000b8000
上記の結果から、次のことがわかります:
append()関数は要素をスライスの最後に追加し、そのスライスを返します。- スライス numSlice の容量は 1、2、4、8、16 のように自動的に拡張され、各拡張後は拡張前の 2 倍になります。
$GOROOT/src/runtime/slice.goのソースコード:
newcap := old.cap
doublecap := newcap + newcap
if cap > doublecap {
newcap = cap
} else {
if old.len < 1024 {
newcap = doublecap
} else {
// 0 < newcapをチェックしてオーバーフローを検出し、
// 無限ループを防ぎます。
for 0 < newcap && newcap < cap {
newcap += newcap / 4
}
// 新しい容量の計算がオーバーフローした場合、
// 新しい容量を要求された容量に設定します。
if newcap <= 0 {
newcap = cap
}
}
}
- まず、新しい要求された容量(cap)が古い容量(old.cap)の 2 倍を超える場合、最終的な容量(newcap)は新しい要求された容量(cap)になります。
- そうでない場合、古いスライスの長さが 1024 未満であれば、最終的な容量 (newcap) は古い容量 (old.cap) の 2 倍になります(newcap=doublecap)。
- そうでない場合、古いスライスの長さが 1024 以上であれば、最終的な容量(newcap)は古い容量(old.cap)から始まり、元の 1/4 を加算し続けます(newcap=old.cap,for {newcap += newcap/4})し、最終的な容量(newcap)が新しい要求された容量 (cap) 以上になるまで続けます。
- 最終的な容量(cap)の計算値がオーバーフローした場合、最終的な容量(cap)は新しい要求された容量(cap)になります。
中国語の文字列は 3*2^n です。
copy()#
スライスは参照型であるため、a と b は実際には同じメモリアドレスを指しています。b を変更すると同時に a の値も変わります。
Go 言語の組み込みのcopy()関数は、あるスライスのデータを別のスライスの空間に迅速にコピーできます。
a := []int{1, 2, 3, 4, 5}
c := make([]int, 5, 5)
copy(c, a) //copy()関数を使用してスライスaの要素をスライスcにコピーします。
fmt.Println(a) //[1 2 3 4 5]
fmt.Println(c) //[1 2 3 4 5]
c[0] = 1000
fmt.Println(a) //[1 2 3 4 5]
fmt.Println(c) //[1000 2 3 4 5]
要素の削除#
a = append(a[:index], a[index+1:]...)
a := []int{30, 31, 32, 33, 34, 35, 36, 37}
// インデックス2の要素を削除します。
a = append(a[:2], a[3:]...)
fmt.Println(a) //[30 31 33 34 35 36 37]
// 基盤となる配列の長さは変わらず、要素は左にシフトされ、右側は最右の要素で補完されます。
スライスをソートします。
sort.Ints(a[:])
ポインタ#
ptr := &v // vの型はT 出力ポインタ型*T 例えば *string *int
a := 10
b := &a
fmt.Printf("a:%d ptr:%p\n", a, &a) // a:10 ptr:0xc00001a078
fmt.Printf("b:%p type:%T\n", b, b) // b:0xc00001a078 type:*int
fmt.Println(&b) // 0xc00000e018
c := *b // ポインタの値を取得(ポインタを介してメモリから値を取得)
fmt.Printf("type of c:%T\n", c)
fmt.Printf("value of c:%v\n", c)
& と * は互補的です。
func modify1(x int) {
x = 100
}
func modify2(x *int) {
*x = 100
}
func main() {
a := 10
modify1(a)
fmt.Println(a) // 10
modify2(&a)
fmt.Println(a) // 100
}
new と make#
new 関数はあまり使用されず、new 関数を使用して得られるのは型のポインタであり、そのポインタが指す値はその型のゼロ値です。
a := new(int)
b := new(bool)
fmt.Printf("%T\n", a) // *int
fmt.Printf("%T\n", b) // *bool
fmt.Println(*a) // 0
fmt.Println(*b) // false
make もメモリ割り当てに使用されますが、new とは異なり、slice、map、chan のメモリ作成にのみ使用され、返される型はこれら 3 つの型変数そのものであり、ポインタ型ではありません。なぜなら、これら 3 つの型は参照型だからです。
var b map[string]int
b = make(map[string]int, 10)
b["沙河娜扎"] = 100
fmt.Println(b)
map#
Go 言語で提供されるマッピング関係のコンテナはmapであり、その内部はハッシュテーブル(hash)を使用して実装されています。Python の辞書に似ています。
map は無秩序なkey-valueに基づくデータ構造で、Go 言語の map は参照型であり、使用する前に初期化する必要があります。
map 型の変数のデフォルト初期値は nil であり、make () 関数を使用してメモリを割り当てる必要があります。
map[KeyType]ValueType
scoreMap := make(map[string]int, 8) // 初期化しないと使用できません。動的拡張を避けるため!
scoreMap["张三"] = 90
scoreMap["小明"] = 100
fmt.Println(scoreMap)
fmt.Println(scoreMap["小明"])
fmt.Printf("type of a:%T\n", scoreMap)
userInfo := map[string]string{
"username": "沙河小王子",
"password": "123456",
}
キーの存在確認#
value, ok := map[key] // okはキーが存在するかどうかのbool値を返します。
v, ok := scoreMap["张三"]
if ok {
fmt.Println(v)
} else {
fmt.Println("該当者なし")
}
map の反復#
for k, v := range scoreMap {
fmt.Println(k, v)
}
for k := range scoreMap {
fmt.Println(k)
}
for _, v := range scoreMap {
fmt.Println(v)
}
注意:map を反復する際の要素の順序は、追加されたキーと値の順序とは関係ありません。
キーと値の削除#
delete(map, key)
指定順序での反復#
func main() {
rand.Seed(time.Now().UnixNano()) //ランダム数の種を初期化します。
var scoreMap = make(map[string]int, 200)
for i := 0; i < 100; i++ {
key := fmt.Sprintf("stu%02d", i) //stuで始まる文字列を生成します。
value := rand.Intn(100) //0〜99のランダム整数を生成します。
scoreMap[key] = value
}
// map内のすべてのキーをスライスkeysに格納します。
var keys = make([]string, 0, 200)
for key := range scoreMap {
keys = append(keys, key)
}
// スライスをソートします。
sort.Strings(keys)
// ソートされたキーに従ってmapを反復します。
for _, key := range keys {
fmt.Println(key, scoreMap[key])
}
}
要素が map 型のスライス#
var mapSlice = make([]map[string]string, 3) // スライスを初期化し、各要素はmapです。
for index, value := range mapSlice {
fmt.Printf("index:%d value:%v\n", index, value)
}
fmt.Println("初期化後")
// スライス内のmap要素を初期化します。
mapSlice[0] = make(map[string]string, 10)
mapSlice[0]["name"] = "小王子"
mapSlice[0]["password"] = "123456"
mapSlice[0]["address"] = "沙河"
for index, value := range mapSlice {
fmt.Printf("index:%d value:%v\n", index, value);
}
値がスライス型の map#
func main() {
var sliceMap = make(map[string][]string, 3)
fmt.Println(sliceMap)
fmt.Println("初期化後")
key := "中国"
value, ok := sliceMap[key]
if !ok {
value = make([]string, 0, 2)
}
value = append(value, "北京", "上海")
sliceMap[key] = value
fmt.Println(sliceMap)
}
関数#
func 関数名(引数 型) 戻り値型 {
関数本体
}
func intSum(x int, y int) int {
return x + y
}
引数同型の省略#
func intSum(x, y int) int {
return x + y
}
可変引数#
func intSum2(x ...int) int {
fmt.Println(x) //xはスライスです。
sum := 0
for _, v := range x {
sum = sum + v;
}
return sum;
}
戻り値#
//名前付き戻り値
func calc(x, y int) (sum, sub int) {
sum = x + y
sub = x - y
return
}
//スライス
func someFunc(x string) []int {
if x == "" {
return nil // []int{}を返す必要はありません。
}
...
}
ローカル変数とグローバル変数が同名の場合、ローカル変数が優先されます。
関数型と変数#
typeキーワードを使用して関数型を定義できます。具体的な形式は次のとおりです:
type calculation func(int, int) int
上記の文はcalculation型を定義します。これは、2 つの int 型の引数を受け取り、int 型の戻り値を返す関数型です。
func main() {
var c calculation // calculation型の変数cを宣言します。
c = add // addをcに代入します。
fmt.Printf("type of c:%T\n", c) // type of c:main.calculation
fmt.Println(c(1, 2)) // addを呼び出すようにcを呼び出します。
f := add // 関数addを変数f1に代入します。
fmt.Printf("type of f:%T\n", f) // type of f:func(int, int) int
fmt.Println(f(10, 20)) // addを呼び出すようにfを呼び出します。
}
関数を引数と戻り値にする#
func add(x, y int) int {
return x + y
}
func calc(x, y int, op func(int, int) int) int {
return op(x, y)
}
func main() {
ret2 := calc(10, 20, add)
fmt.Println(ret2) //30
}
func do(s string) (func(int, int) int, error) {
switch s {
case "+":
return add, nil
case "-":
return sub, nil
default:
err := errors.New("認識できない演算子")
return nil, err
}
}
匿名関数#
関数内部で関数を定義します。
func main() {
// 匿名関数を変数に保存します。
add := func(x, y int) {
fmt.Println(x + y)
}
add(10, 20) // 10 + 20を出力します。
// 自実行関数:匿名関数を定義した後に()を付けて直接実行します。
func(x, y int) {
fmt.Println(x + y)
}(10, 20)
}
クロージャ#
クロージャは、関数とその関連する参照環境の組み合わせで構成される実体を指します。簡単に言えば、クロージャ=関数+参照環境です。
func adder() func(int) int {
var x int
return func(y int) int {
x += y
return x
}
}
func main() {
var f = adder()
fmt.Println(f(10)) //10
fmt.Println(f(20)) //30
fmt.Println(f(30)) //60
f1 := adder()
fmt.Println(f1(40)) //40
fmt.Println(f1(50)) //90
}
defer#
defer文は、その後に続く文を遅延処理します。deferに属する関数が戻る直前に、遅延処理された文がdeferで定義された逆順で実行されます。つまり、最初にdeferされた文が最後に実行され、最後にdeferされた文が最初に実行されます。
func main() {
fmt.Println("開始")
defer fmt.Println(1)
defer fmt.Println(2)
defer fmt.Println(3)
fmt.Println("終了")
}
/*
開始
終了
3
2
1
*/
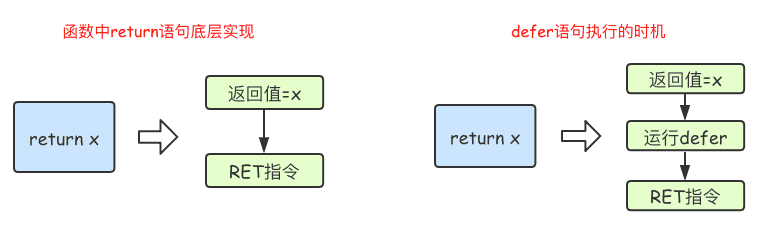
//面接問題 deferで遅延実行する関数を登録する際、その関数のすべての引数はその値を確定する必要があります。
func calc(index string, a, b int) int {
ret := a + b
fmt.Println(index, a, b, ret)
return ret
}
func main() {
x := 1
y := 2
defer calc("AA", x, calc("A", x, y))
x = 10
defer calc("BB", x, calc("B", x, y))
y = 20
}
/*
A 1 2 3 //defer calc("AA", 1, 3)
B 10 2 12 //defer calc("BB", 10, 12)
BB 10 12 22
AA 1 3 4
*/
組み込み関数#
| 組み込み関数 | 説明 |
|---|---|
| close | 主に channel を閉じるために使用 |
| len | 長さを求めるために使用します。例えば string、array、slice、map、channel |
| new | メモリを割り当てるために使用され、主に値型(int、struct など)を割り当てます。返されるのはポインタです。 |
| make | メモリを割り当てるために使用され、主に参照型(chan、map、slice など)を割り当てます。 |
| append | 要素を配列や slice に追加するために使用 |
| panic と recover | エラー処理に使用 |
Go 言語では現在(Go1.12)、例外メカニズムはありませんが、panic/recoverモードを使用してエラーを処理します。 panicはどこでも引き起こすことができますが、recoverはdeferで呼び出された関数内でのみ有効です。
func funcA() {
fmt.Println("func A")
}
func funcB() {
defer func() {
err := recover()
//プログラムがpanicエラーを引き起こした場合、recoverを介して回復できます。
if err != nil {
fmt.Println("Bで回復")
}
}()
panic("Bでpanic")
}
func funcC() {
fmt.Println("func C")
}
func main() {
funcA()
funcB()
funcC()
}
recover()は必ずdeferと一緒に使用する必要があります。deferは必ずpanicを引き起こす可能性のある文の前に定義する必要があります。
fmt 標準ライブラリ#
fmt パッケージは、C 言語の printf や scanf のようなフォーマットされた I/O を実装しています。主に外部への出力と入力の取得の 2 つの部分に分かれています。
Print#
func main() {
fmt.Print("ターミナルにこの情報を印刷します。") //改行なし
name := "沙河小王子"
fmt.Printf("私は:%s\n", name)
fmt.Println("ターミナルに単独の行を表示します。")
}
FPrint#
Fprintシリーズの関数は、内容をio.Writerインターフェース型の変数wに出力します。通常、この関数を使用してファイルに内容を書き込みます。
// 標準出力に内容を書き込みます。
fmt.Fprintln(os.Stdout, "標準出力に内容を書き込みます。")
fileObj, err := os.OpenFile("./xx.txt", os.O_CREATE|os.O_WRONLY|os.O_APPEND, 0644)
if err != nil {
fmt.Println("ファイルを開く際にエラーが発生しました。err:", err)
return
}
name := "沙河小王子"
// 開いたファイルハンドルに内容を書き込みます。
fmt.Fprintf(fileObj, "ファイルに書き込む情報:%s", name)
io.Writerインターフェースを満たす型はすべて書き込みをサポートします。
Sprint#
Sprintシリーズの関数は、渡されたデータを生成し、文字列を返します。
s3 := fmt.Sprintln("沙河小王子")
Errorf#
e := errors.New("元のエラーe")
w := fmt.Errorf("エラーをラップしました%w", e)
Scan#
fmt.Scan(&name, &age, &married)
fmt.Scanf("1:%s 2:%d 3:%t", &name, &age, &married)
fmt.Scanln(&name, &age, &married)
他に Fscan、Sscan があります。
bufio.NewReader#
func bufioDemo() {
reader := bufio.NewReader(os.Stdin) // 標準入力から読み取りオブジェクトを生成します。
fmt.Print("内容を入力してください:")
text, _ := reader.ReadString('\n') // 改行で終了 空白も読み取ります。
text = strings.TrimSpace(text)
fmt.Printf("%#v\n", text)
}
構造体#
Go 言語には「クラス」の概念がなく、「クラス」の継承などのオブジェクト指向の概念もサポートされていません。Go 言語では、構造体の埋め込みとインターフェースを組み合わせることで、オブジェクト指向よりも高い拡張性と柔軟性を持っています。
カスタム型#
カスタム型は、新しい型を定義したものです。組み込みの基本型に基づいて定義することも、struct を使用して定義することもできます。
//MyIntをint型として定義します。
type MyInt int
typeキーワードを使用した定義により、MyIntは新しい型であり、intの特性を持ちます。
型エイリアス#
型エイリアスの規則:TypeAlias は Type のエイリアスであり、本質的に TypeAlias と Type は同じ型です。
type TypeAlias = Type
以前見たruneとbyteは型エイリアスです。
type byte = uint8
type rune = int32
構造体の定義#
typeとstructキーワードを使用して構造体を定義します。具体的なコード形式は次のとおりです:
type 型名 struct {
フィールド名 フィールド型
フィールド名 フィールド型
…
}
type person struct {
name string
city string
age int8
}
type person1 struct {
name, city string
age int8
}
ここで:
- 型名:カスタム構造体の名前を識別します。同じパッケージ内で重複してはいけません。
- フィールド名:構造体のフィールド名を示します。構造体内のフィールド名は一意でなければなりません。
- フィールド型:構造体フィールドの具体的な型を示します。
インスタンス化#
構造体がインスタンス化されるときにのみ、実際にメモリが割り当てられます。インスタンス化された後でなければ、構造体のフィールドを使用できません。
構造体自体も型の一種であり、組み込み型のようにvarキーワードを使用して構造体型を宣言できます。
var 構造体インスタンス 構造体型
基本インスタンス化
type person struct {
name string
city string
age int8
}
func main() {
var p1 person
p1.name = "沙河娜扎"
p1.city = "北京"
p1.age = 18
fmt.Printf("p1=%v\n", p1) //p1={沙河娜扎 北京 18}
fmt.Printf("p1=%#v\n", p1) //p1=main.person{name:"沙河娜扎", city:"北京", age:18}
}
匿名構造体、一時的なデータ構造に使用します。
func main() {
var user struct{Name string; Age int}
user.Name = "小王子"
user.Age = 18
fmt.Printf("%#v\n", user)
}
ポインタ型構造体、new を使用してアドレスを割り当てます。
var p2 = new(person)
//&を使用して構造体のアドレスを取得する操作は、構造体型をnewでインスタンス化することに相当します。
p3 := &person{}
fmt.Printf("%T\n", p2) //*main.person
fmt.Printf("p2=%#v\n", p2) //p2=&main.person{name:"", city:"", age:0}
//構造体ポインタを使用して直接構造体メンバーにアクセスすることができます。
p2.name = "小王子"
p2.age = 28
p2.city = "上海"
fmt.Printf("p2=%#v\n", p2) //p2=&main.person{name:"小王子", city:"上海", age:28}
初期化#
初期化されていない構造体は、そのメンバー変数が対応する型のゼロ値になります。初期化は値を割り当てることを意味します。
キーバリューで初期化します。
p5 := person{
name: "小王子",
city: "北京",
age: 18,
}
構造体ポインタを初期化します。
p6 := &person{
name: "小王子",
city: "北京",
age: 18,
}
リストで初期化します。
p8 := &person{
"沙河娜扎",
"北京",
28,
}
メモリレイアウト#
構造体は連続したメモリを占有し、空の構造体はスペースを占有しません。
コンストラクタ#
他の言語のオブジェクト指向のコンストラクタのように、Go はインターフェースプログラミングを行います。