
コース紹介#
フェーズ 1:基礎から上級へ#
3 つのプロジェクト
- ATM + ショッピングカート:手続き型
- 選択科目システム:オブジェクト指向
- コンピュータウイルス:プログラム、サーバー、クライアント
フェーズ 2:ビジネスプロジェクト#
- BBS
- ルフィ学城
- WeChat ミニプログラム
- クローラー
- データ分析:金融量的取引
- 自動化運用:cmdb、コードリリース
- GO 言語開発
- 人工知能分野
コンピュータ#
コンピュータの 5 大構成要素#
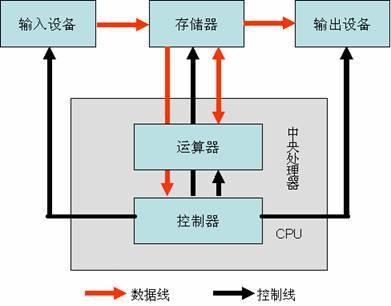
- CPU 中央処理装置
- コントローラー:他のすべてのコンポーネントを制御
- 演算器:数学演算と論理演算
- メモリ io デバイス:データアクセス
- RAM:電気ベースで、電源が切れるとデータが失われ、一時的なアクセスに使用
- 外部ストレージ:ハードディスク、磁気ベースで、アクセスが遅く、永続的に保存
- 入力デバイス:キーボード、マウス
- 出力デバイス:ディスプレイ、プリンター
オペレーティングシステム#
概念#
- コンピュータハードウェアを制御
- ハードウェアの複雑な操作をカプセル化
ソフトウェア
- アプリケーションソフトウェア
- システムソフトウェア
コンピュータアーキテクチャの三層構造#
- アプリケーション
- オペレーティングシステム
- コンピュータハードウェア
プラットフォームとクロスプラットフォーム#
プラットフォーム:
- オペレーティングシステム
- コンピュータハードウェア
その他#
プログラムと三大コアハードウェア#
プログラム:ハードディスク -> メモリ
CPU はメモリから命令を読み取り実行
CPU 詳細#
CPU の分類と命令セット#
- X86-32bit:intel
- x86-64bit:AMD
命令セットとは、CPU 内で計算とコンピュータシステムを制御するための命令の集合です。
- 簡素命令セット RISC:命令が短く、安定
- 複雑命令セット CISC:命令が長く、豊富
X86-64#
-
x86:intel が世界初の CPU8086 を発明したため、このアーキテクチャのモデルを総称して x86 と呼ぶ。
-
64 ビット:CPU が一度にメモリから何ビットのバイナリ命令を取得できるか。
CPU には下位互換性があります。
レジスタ#
CPU と同じ材料で、メモリよりも速い。CPU が使用する重要なデータを保存し、CPU のデータ取得速度を向上させます。
カーネルモードとユーザーモード#
2 種類のプログラム
- オペレーティングシステム:カーネルモード、ハードウェアを制御する命令セットと演算命令セットを呼び出す
- アプリケーション:ユーザーモード、演算関連の命令セットのみを呼び出す
したがって、2 つの状態が頻繁に切り替わります。
マルチスレッドとマルチコアチップ#
ムーアの法則。
シングルコアデュアルスレッド、つまり 1 つの CPU が 2 つの CPU の作業を行う、擬似並列、偽デュアルコア。
4 コア 8 スレッド:各 CPU が 2 スレッド。
- intel:すべてのコアが 1 つの L2 キャッシュを呼び出す
- AMD:各コアに個別の L2 キャッシュを割り当てる
メモリ io 関連#
- レジスタ L1:32 ビット 32x32、64 ビット 64x64
- 高速キャッシュ L2:CPU は最初に高速キャッシュを探し、高速キャッシュがヒットしなければメモリを探す
- メモリ
- ハードディスク
- 磁気テープ
速度の速さ - 遅さ
RAM#
ランダムアクセスメモリ
ROM#
読み取り専用メモリ、速度はメモリと同じ。したがって、一般的には工場出荷時の重要なプログラムの保存に使用されます。例えば BIOS。
CMOS#
これも揮発性です。速度は遅い。消費電力は非常に低い。マザーボードにはマザーボードバッテリーがあり、時計チップに電力を供給し、計算後に CMOS に保存します。
ハードディスク構造#
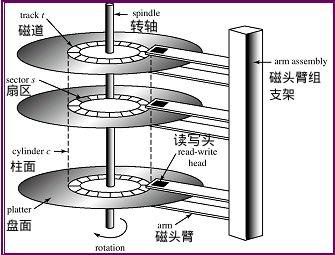
ハードディスク:
- 機械式ハードディスク、つまりディスクは機械的な回転に依存します。
- 磁道:1 周のデータ bit(二進数)-Byte(バイト)-kB、実際にはハードディスクメーカーは 1000 で記録します。
- セクター:512 バイト、つまりハードディスクが一度に読み書きする最小単位。オペレーティングシステムは 1 回の読み取りで 1 ブロック、つまり 8 つのセクター = 4096 バイトを読み取ります。
- シリンダー:同じ半径の磁道が重なり合って仮想シリンダーを形成します。
- パーティション:2 つのシリンダー間の部分です。
- ソリッドステートドライブ
IO 遅延#
ハードディスクの読み書き速度は非常に速いが、遅いのはデータを探す時間です。
- 平均シーク時間
- 平均遅延時間:最低はハードディスクが半周回転する時間
IO 遅延は上記 2 つの合計です。
プログラムの最適化の核心的な方法は、ハードディスクからの読み書きを減らし、できるだけメモリから行うことです。
仮想メモリスワップ#
物理メモリが不足しているときにディスク上に割り当てます。IO 遅延を引き起こす可能性があります。
IO デバイス#
含まれます
- デバイス制御:ドライバ
- デバイス自体
バス#
マザーボード上の各コンポーネントの相互作用を接続します。
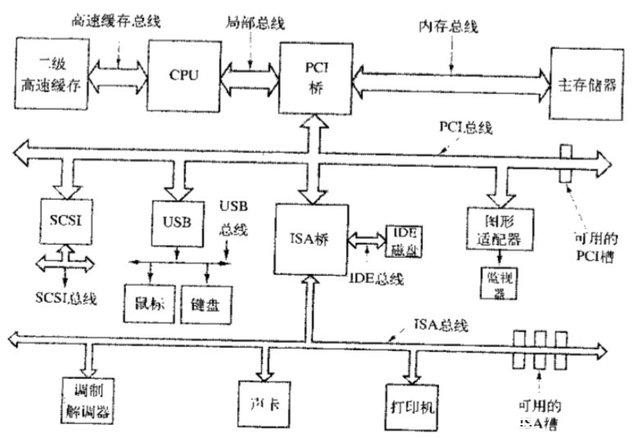
- PCI ブリッジ:北ブリッジ、高速デバイスを接続
- ISA ブリッジ:南ブリッジ、低速デバイスを接続
オペレーティングシステムの起動プロセス#
BIOS: 基本入出力システム、工場出荷時に ROM デバイスに書き込まれます。
起動プロセス:
- コンピュータに電源を入れる
- BIOS がハードウェアの正常性を監視
- BIOS が CMOS メモリのパラメータを読み取り、起動デバイスを選択
- 起動デバイスから最初のセクターの内容を読み取る(MBR 主ブートレコード 512 バイト、最初の 446 ビットがブート情報、次の 64 ビットがパーティション情報、最後の 2 ビットがフラグ)
- パーティション情報に基づいて BootLoader 起動ロードモジュールを読み込み、オペレーティングシステムを起動
- オペレーティングシステムが BIOS に問い合わせて構成情報を取得し、ドライバをロードします。
Python 入門#
プログラミング言語の紹介#
- 機械語
- アセンブリ言語
- 高級言語
- コンパイル型:c->gcc コンパイラ -> 機械語、実行効率が高い
- インタプリタ型:py-> バイトコード -> インタプリタ(一行ずつ)-> 機械、クロスプラットフォーム性が強い
python 紹介#
- インタプリタ型
- 構文スタイル:PEP8 規範
インタプリタ#
インタプリタは任意の言語で書くことができ、CPython、Jpython。
2.6-2008
2.7-2010 後にリリースされた移行バージョン
3.0-2008
3.1-2009
3.2-2011
python プログラムを実行する 2 つの方法#
- インタラクティブ
- スクリプト
プログラム実行の 3 ステップ#
- インタプリタを起動
- インタプリタが py をメモリに読み込む
- インタプリタが解釈して実行
変数と基本データ型#
変数#
3 つの構成要素#
変数名 代入演算子 変数名
変数名#
小文字とアンダースコアを推奨
変数値の 3 つの特徴#
- id:変数値のメモリアドレス
id()
- type
type()
- value
可変型と不可変型#
- 可変型:value を変更してもメモリアドレス id は変わらない
- set
- list
- dict
- 不可変型:value を変更すると id も変わる
- number
- bool
- string
- tuple
is と ==#
- is は左右の変数のメモリアドレスが同じかどうかを比較
- == は変数の値を比較
小整数オブジェクトプール#
インタプリタが起動すると、メモリ内に一連のメモリスペースを事前に確保し、よく使われる整数(-5, 256)を保存します。
IDE の小整数プールはさらに大きいです。
定数#
python の構文には定数の概念はありません!
全て大文字は定数を表すだけで、実際には変数です。
基本データ型#
文字列#
単一、二重、三重引用符で定義可能で、ネストする場合は単二が逆であるか、エスケープする必要があります。
print('-' * 10)
# -----------
リスト#
メモリには値のメモリアドレスが保存され、値は保存されません!
もし list2 = list1 であれば、両者は同じヒープを指し、値を変更すると両方とも変更されます。
深浅コピー:
- 浅コピー:リストの第一層のメモリアドレスをコピーしますが、可変型がある場合は依然として連結されます。
list2 = list1.copy()
- 深コピー:完全に独立したコピーを作成し、不可変型の id は変わらず、可変型の id は変更されます。
import copy
list3 = copy.deepcopy(list1)
辞書#
a = {
"key":"value"
"1":1,
"2":"qwe"
}
ガベージコレクションメカニズム GC#
参照カウント#
ガベージ:変数値が変数名にバインドされていない
参照カウント:特定の値にバインドされている変数の数、python はカウントが 0 の値を削除します。
del x # 変数と値のバインディングを解除
直接参照、間接参照
マーク&クリア#
循環参照の問題があり、メモリリークを引き起こす可能性があります。
メモリスタック領域には変数名が保存され、ヒープ領域には値が保存されます。
世代回収#
複数回スキャンしても回収されなかった変数は、一般的な変数と見なされ、そのスキャン頻度は低下します。
ユーザーインタラクション#
入力#
input() # strとして保存
# python2
raw_input() # strとして保存
input() # ユーザーに明確なデータ型の入力を要求し、入力されたものがその型になります。
フォーマット出力#
- % フォーマット出力
print("name: %(name)s, age:%(age)d" % {"name": "a", "age": 10})
# %sは任意の型を受け入れます。
- str.format
print("name: {name}, age:{age}".format(name = "a", age = 10))
- f
print(f"name: {name}, age:{age}")
基本演算子#
算術演算子#
10 // 3 # 整数部分のみ保持、つまり整数除算
3 ** 10 # 指数
10 % 3 # 余りを取得
比較演算子#
1 != 2
1 < x < 3
代入演算子#
- 変数代入
a = 1
- 増分代入
a += 1
b *= 1
- チェーン代入
z = y = x = 10
- 交差代入
m, n = n, m
- アンパック代入
list = [1, 2, 3, 4]
a, b, c, d = list
x, y, *_ = list # 最初の2つを取得
*_ , x, y = list # 最後の2つを取得
# 辞書のアンパックではキーを取得します。
論理演算子#
暗黙のブール:すべての値、0、None、False、Null、空値を除いては True です。
優先順位 not>and>or
ショートサーキット演算:左から右に条件を読み取り、連続する and のいずれかが false であれば、右に進まず、その位置の値を返します。
メンバー演算子 in#
"a" in "abc"
1 in [1, 2, 3]
身分演算子 is#
フロー制御#
if#
if 16 < a < 20:
elif 条件は上から下へ、上の条件が満たされない場合のみ次の条件に進みます。
while#
条件ループ
while+else#
ループが正常に終了し、break されなかった場合、else が実行されます。
while True:
...
else:
...
for#
反復ループ
for variable in Iterable object:
...
for i in range(1, 100):
...
for+else#
range#
# py2
>>> range(0, 5)
[0, 1, 2, 3, 4]
#py3 最適化
>>> range(0,5)
range(0,5)
print#
print("hello", end="*") # 終了をカスタマイズ、デフォルトは改行
基本データ型と組み込みメソッド#
数字型#
int#
python3 には long 型はありません。
int('10')
bin(11) # 0b1011 0bで始まるのは二進数
oct(11) # 0o13 8進数
hex(11) # 0xb 16進数
int(int('0b1011', 2)) # 二進数から10進数に変換
float#
float('11')
虚数#
x = 10 + 2j
x.real #10
x.imag #2
文字列#
# 不可変で、全体として扱われ、特定の文字を単独で変更することはできません。
str(10)
msg = "hello"
# スライス
msg[0] # h
msg[-1] # o
msg[0:5] # hello 先頭を含み、末尾を含まない
msg[0:5:2] # hlo
msg[5:0:-1] # olle
"alex" in "alexxxx" # true
"alex" not in "alexxxx" # false
msg = " eee "
res = msg.strip() # デフォルトで両端の空白を削除、文字列は不可変なので新たに代入する必要があります。
msg = "***eee***"
res = msg.strip("*") # stripは両端のみを削除し、中央は削除しません。
res = msg.lstrip()
res = msg.rstrip()
# 分割:特定の文字で文字列を分割し、リストを返します。
res = msg.split(":", 1) # デフォルトで空白で分割、分割回数は左から数えます。
res = msg.lsplit(":", 1)
res = msg.rsplit(":", 1) # 右から左に分割
res2 = ":".join(res) # :を区切り文字として結合
res = msg.lower() # 小文字に変換
res = msg.upper()
res = msg.startswith("aaa") # True 何で始まるか
res = msg.endswith("aaa")
res = msg.replace("you", "me" ,1) # 文字列の置換、回数指定
"123".isdigit() # 純粋な数字
msg.find("e") # インデックスを返し、見つからない場合は-1を返す
msg.index("e") # インデックスを返し、見つからない場合はエラーを発生させる
msg.count("e") # サブ文字列の出現回数を数える
"分割線".center(50, "*") # 両側を*で埋める
"分割線".ljust(50, "*") # 右側を埋める
"分割線".rjust(50, "*")
"分割線".zfill(50) # 左側を0で埋める
# is 判定シリーズ ドキュメントを参照
isalpha()
isdigit()
isdecimal() # アラビア数字のみを認識 py3はデフォルトでunicode
isnumeric() # 漢字やアラビア数字を認識可能